
Grazie all’intelligenza artificiale anche i più famosi quadri e le vecchie foto sono animate
I ricercatori di machine learning hanno prodotto un sistema che è in grado di ricreare un movimento realistico umano da un singolo fotogramma di un volto di una persona, aprendo la possibilità di animare non solo le foto ma anche i quadri. Non è ancora perfezionata, ma quando è al lavoro è – come tutte le tecnologie di Intelligenza Artificiali attuali – inquietante e allo stesso tempo affascinante.
Il modello è riportare in un documento pubblicato dal Centro AI di Samsung. Si tratta di un nuovo metodo di applicazione dei punti di riferimento facciali su una sorgente di un volto – qualsiasi testa parlante va bene – ai dati facciali di un volto di destinazione, facendo in modo che il volto di destinazione imiti quello che il volto di sorgente esprime.
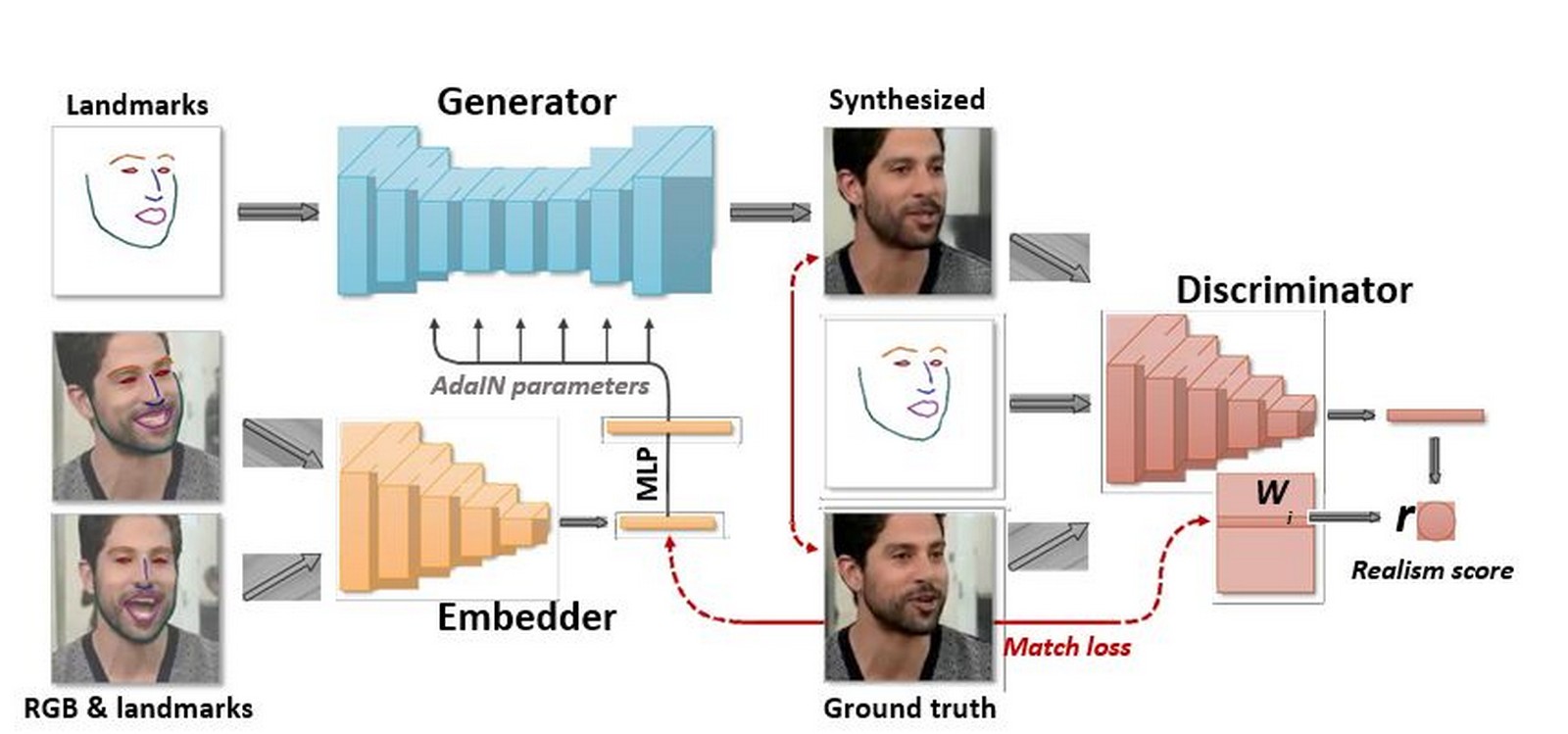
Foto: Arxiv
Ciò non è di per sé qualcosa di nuovo – fa parte di un intero problema riguardante le immagini sintetiche, che sta affrontando il mondo dell’AI in questo momento. Infatti, si può già fare in modo che un volto in un video rifletta un volto in un altro per imitare quello che uno dei due dice o cosa sta guardando. Tuttavia la maggior parte di questi modelli richiede una notevole quantità di dati, per esempio un minuto o due di video da analizzare.
Il lavoro dei ricercatori Samsung di Mosca, tuttavia, mostra che utilizzando una singola immagine del volto di una persona, è possibile generare un video della persona che parla, si gira e fa espressioni ordinarie – con una fedeltà così convincente, sebbene lungi dall’essere impeccabile. Questo è possibile anticipando il processo di identificazione dei punti di riferimento facciali con un’enorme quantità di dati, rendendo il modello altamente efficiente nel trovare le parti del volto di destinazione che corrispondono a quello della fonte.

Foto: Techcrunch
Più dati possiede il sistema, meglio è, ma può farlo solamente con un’immagine – viene chiamato single-shot learning (apprendimento a colpo singolo) – e uscirsene alla grande. Può essere quindi possibile scattare una foto di Einstein o Marilyn Monroe, o anche della Gioconda, e farli muovere e parlare come una vera persona.

Foto: Techcrunch
Il modello utilizza anche la Generative Adversarial Network, che essenzialmente mette due modelli l’uno contro l’altro: uno cerca di ingannare l’altro facendogli pensare che quello che sta creando sia “reale”. Tramite questi strumenti i risultati raggiungono un certo livello di realismo impostato dai creatori – il modello “discriminatore” deve essere al 90% sicuro che si tratti di un volto umano affinché il processo vada avanti.

Foto: Arxiv
È fantastico che il modello abbia raggiunto questi risultati e che funzioni così bene. Si noti, tuttavia, che questo funziona solo sul viso e sulla parte superiore del busto: non è ancora possibile fare schioccare le dita o fare ballare la Gioconda. Non ancora, comunque.